


vm 문제로 보인다.
여러 vm 문제를 풀어보면서 터득한 루틴이 있다.
- instruction 분석
- disassembler 간단 제작 후 전체 코드 뽑아보기
- 동적 실행으로 조건문/반복문 판별하며 흐름 분석
- 각 instruction 들이 모인 코드 덩이들의 목적이나 역할 분석 - 함수화
- 정연산 짜기
- 복호화 코드 짜기
1. instruction 분석

모든 연산을 fpu 위에서 한다.
fpu 에 대해 아예 몰랐었는데, 이번에 많이 알게 되었다.
먼저 fpu 는 8개의 st register를 stack 구조로 관리한다.
그리고 top 을 이동시키며 push/pop 을 구현하기 때문에 8번 push/pop 하면 제자리로 돌아오게 된다.
예를 들어보자면

위 그림과 같다.
top 을 기준으로 st0 부터 st1 st2 ... st7 까지 정한다.
fld__ instruction : push ___
fxch st_ : swap(st[0], st[_])
fdecstp : top++
fincstp : top--
fcom : st[0] st[1] 비교 후 flag 설정
이정도를 사용하며, 뒤에 p 가 붙은 instruction들은 연산 후 pop 한다는 소리이다.
2. disassembler 제작
- vm.py
# vm.py
from collections import deque
import math
DYNAMIC_DEBUG_MODE = True
vm = bytes.fromhex('23 38 41 24 43 54 24 43 54 73 24 38 38 41 43 27 41 24 43 54 73 24 38 38 23 51 43 43 43 54 73 23 24 41 24 38 43 43 54 73 23 38 38 51 43 43 24 43 54 73 23 38 38 43 43 54 22 41 73 21 62 94 01 62 B2 01 62 84 01 39 05 3F 11 F4 FF 29 57 81 0E 40 65 03 00 32 53 32 3A 39 5E 57 F3 B4 A3 8C 7F BA 07 40 65 03 00 31 53 31 3A 62 67 01 62 85 01 62 57 01 39 B7 73 80 E1 B0 72 87 F2 03 40 65 03 00 32 53 32 3A 39 3F 68 A3 E4 04 9A 3B 8F 07 40 65 03 00 31 53 31 3A 62 3A 01 62 58 01 62 2A 01 39 54 27 B5 B6 95 52 5D CD 0B 40 65 03 00 32 53 32 3A 39 28 91 9A 4A A2 71 37 91 07 40 65 03 00 31 53 31 3A 62 0D 01 62 2B 01 62 FD 00 39 A3 86 14 05 41 8C 74 E5 0B 40 65 03 00 32 53 32 3A 39 BC 61 ED F2 E9 6E C1 AB 06 40 65 03 00 31 53 31 3A 62 E0 00 62 FE 00 62 D0 00 39 88 92 3A E0 69 3F 54 92 06 40 65 03 00 32 53 32 3A 39 0F D1 BE E3 39 A1 96 C5 05 40 65 03 00 31 53 31 3A 62 B3 00 62 D1 00 62 A3 00 39 83 EA 7B 97 E5 4C D3 EA 06 40 65 03 00 32 53 32 3A 39 87 EF B0 D1 5C FE 86 AD 04 40 65 03 00 31 53 31 3A 62 86 00 62 A4 00 62 76 00 39 19 42 6C D4 CA F6 F2 D9 09 40 65 03 00 32 53 32 3A 39 EF FF DA 15 13 EA AE DB 06 40 65 03 00 31 53 31 3A 62 59 00 62 77 00 62 49 00 39 FE 13 97 DF CD 12 7E F0 0A 40 65 03 00 32 53 32 3A 39 1C AF CF 1F 96 45 41 A5 06 40 65 03 00 31 53 31 3A 72 23 38 43 25 41 24 38 43 43 54 64 05 00 3A 3A 63 7D 00 3A 39 5A 88 34 14 A0 C3 05 BD FE 3F 64 8E 00 63 6B 00 32 38 32 38 32 43 32 41 32 61 72 62 42 00 72 62 3E 00 22 22 41 23 43 43 24 38 41 54 24 38 43 43 54 24 43 54 44 38 52 42 43 31 61 72 62 21 00 72 62 1D 00 22 22 41 23 43 43 24 38 41 54 24 38 43 43 54 24 43 54 44 38 53 22 41 31 52 43 43 31 61 31 23 38 43 23 43 54 22 41 67 0F 00 24 38 43 24 43 25 41 24 43 54 68 02 00 31 61 23 25 43 24 41 23 38 43 43 54 73 23 24 41 24 38 43 43 54 73 22 23 41 24 38 43 43 54 73 63 21 00 23 22 45 41 24 38 38 43 43 43 54 73 24 38 26 23 41 24 41 43 43 54 73 23 38 43 24 43 54 73 63 00 00 23 38 43 54 73 71 00')
INPUT = b'zer0pts{TSET_1234_abcd}\n'
inp_p = 0
p = 0
v = 0
isExit = False
reg = [0 for _ in range(8)]
top = 0
loopCnt = 0
indexList = []
pp = 0
while not isExit:
c = vm[p if DYNAMIC_DEBUG_MODE else pp]
# if DYNAMIC_DEBUG_MODE:
# if p not in indexList:
# indexList.append(p)
# else:
# loopCnt += 1
# print('*'*10 + f'loop {loopCnt}')
# print(indexList)
# indexList = [p]
# input()
offset = 0
if DYNAMIC_DEBUG_MODE:
print(f'[{p:4d}] : {chr(c)}\t{round(reg[top % 8])}\t{round(reg[(top + 1) % 8])}', end='\t')
else:
print(f'[{pp:4d}] : {chr(c)}\t', end='\t')
if p == 80:
for i in range(8):
print(reg[(top + i) % 8], end=' ')
input()
if DYNAMIC_DEBUG_MODE:
p += 1
else:
pp += 1
# bcdefghi
if 0 <= c - 0x62 <= 0xD:
if DYNAMIC_DEBUG_MODE:
offset = int.from_bytes(vm[p:p+2], 'little', signed=True)
p += 2
else:
offset = int.from_bytes(vm[pp:pp+2], 'little', signed=True)
pp += 2
c = chr(c)
match c:
case '!':
print('PUSH 0', end='')
top -= 1
reg[top % 8] = 0
case '"':
print('PUSH 1', end='')
top -= 1
reg[top % 8] = 1
case '#':
print('PUSH PI', end='')
top -= 1
reg[top % 8] = math.pi
case '$':
print('PUSH log2_10' + str(round(math.log2(10))), end='')
top -= 1
reg[top % 8] = math.log2(10)
case '%':
print('PUSH log2_e' + str(round(math.log2(math.e))), end='')
top -= 1
reg[top % 8] = math.log2(math.e)
case '&':
print('PUSH log10_2' + str(round(math.log10(2))), end='')
top -= 1
reg[top % 8] = math.log10(2)
case '\\':
print('PUSH ln2' + str(round(math.log(math.e, 2))), end='')
top -= 1
reg[top % 8] = math.log(math.e, 2)
case c if c in '1234567':
print(f'swap {0} {int(c)}', end='')
reg[top % 8], reg[(top + int(c)) % 8] = reg[(top + int(c)) % 8], reg[top % 8]
case '8':
print('DUP', end='')
reg[(top - 1) % 8] = reg[top % 8]
top -= 1
case '9':
top -= 1
reg[top % 8] = int.from_bytes(vm[p:p+10], 'little')
if DYNAMIC_DEBUG_MODE:
p += 10
else:
pp += 10
case ':':
print('POP', end='')
top += 1
case 'A':
if DYNAMIC_DEBUG_MODE:
print(f'ADD {reg[top % 8]} {reg[(top+1)%8]}', end='')
else:
print('ADD', end='')
tmp = reg[top % 8]
top += 1
reg[top % 8] += tmp
case 'B':
if DYNAMIC_DEBUG_MODE:
print(f'SUB {reg[top % 8]} {reg[(top+1)%8]}', end='')
else:
print('SUB', end='')
tmp = reg[top % 8]
top += 1
reg[top % 8] -= tmp
case 'C':
if DYNAMIC_DEBUG_MODE:
print(f'MUL {reg[top % 8]} {reg[(top+1)%8]}', end='')
else:
print('MUL', end='')
tmp = reg[top % 8]
top += 1
reg[top % 8] *= tmp
case 'D':
if DYNAMIC_DEBUG_MODE:
print(f'DIV {reg[top % 8]} {reg[(top+1)%8]}', end='')
else:
print('DIV', end='')
tmp = reg[top % 8]
top += 1
reg[top % 8] /= tmp
case 'E':
print('NEG', end='')
reg[top % 8] = -reg[top % 8]
case 'Q':
reg[top % 8] = math.sqrt(reg[top % 8])
case 'R':
reg[top % 8] = math.sin(reg[top % 8])
case 'S':
reg[top % 8] = math.cos(reg[top % 8])
case 'T':
reg[top % 8] = round(reg[top % 8])
case 'a':
v = round(reg[top % 8])
if DYNAMIC_DEBUG_MODE:
print(f'RET\t{v}', end='\t')
else:
print('RET', end='')
top += 1
p = v
case 'b':
if DYNAMIC_DEBUG_MODE:
print(f'CALL\t{p+offset}', end='\t')
else:
print(f'CALL\t{pp+offset}', end='\t')
v = p
top -= 1
reg[top % 8] = v
p += offset
case 'c':
print(f'JMP\t{p if DYNAMIC_DEBUG_MODE else pp +offset}', end='\t')
p += offset
case 'd':
print(f'JE\t{p if DYNAMIC_DEBUG_MODE else pp +offset}', end='\t')
if reg[top % 8] == reg[(top + 1) % 8]:
p += offset
top += 1
case 'e':
print(f'JNE\t{p if DYNAMIC_DEBUG_MODE else pp +offset}', end='\t')
if reg[top % 8] != reg[(top + 1) % 8]:
p += offset
top += 1
case 'f':
print(f'JGE\t{p if DYNAMIC_DEBUG_MODE else pp +offset}', end='\t')
if reg[top % 8] >= reg[(top + 1) % 8]:
p += offset
top += 1
case 'g':
print(f'JG\t{p if DYNAMIC_DEBUG_MODE else pp +offset}', end='\t')
if reg[top % 8] > reg[(top + 1) % 8]:
p += offset
top += 1
case 'h':
print(f'JLE\t{p if DYNAMIC_DEBUG_MODE else pp +offset}', end='\t')
if reg[top % 8] <= reg[(top + 1) % 8]:
p += offset
top += 1
case 'i':
print(f'JL\t{p if DYNAMIC_DEBUG_MODE else pp +offset}', end='\t')
if reg[top % 8] < reg[(top + 1) % 8]:
p += offset
top += 1
case 'q':
isExit = True
case 'r':
if inp_p < len(INPUT):
print(chr(INPUT[inp_p]),end='')
v = INPUT[inp_p]
inp_p += 1
top -= 1
reg[top % 8] = v
case 's':
v = round(reg[top % 8])
top += 1
print(chr(v), end='')
print()dynamic 모드를 설정할 수 있는데, disable 하면 코드를 실행하지 않고 disassemble 만 수행한다.
dynamic 모드에서는 실제로 실행시켜 값들을 확인하고 흐름을 분석할 수 있다.
CALL / RET 은 각각 b / a instruction 인데, 현재 EIP(vm pointer) 를 push 하고 pop / jmp 하는 것을 보고 알아내었다.
- code
[ 0] : # PUSH PI
[ 1] : 8 DUP
[ 2] : A ADD
[ 3] : $ PUSH log2_103
[ 4] : C MUL
[ 5] : T
[ 6] : $ PUSH log2_103
[ 7] : C MUL
[ 8] : T
[ 9] : s F
[ 10] : $ PUSH log2_103
[ 11] : 8 DUP
[ 12] : 8 DUP
[ 13] : A ADD
[ 14] : C MUL
[ 15] : '
[ 16] : A ADD
[ 17] : $ PUSH log2_103
[ 18] : C MUL
[ 19] : T
[ 20] : s I
[ 21] : $ PUSH log2_103
[ 22] : 8 DUP
[ 23] : 8 DUP
[ 24] : # PUSH PI
[ 25] : Q
[ 26] : C MUL
[ 27] : C MUL
[ 28] : C MUL
[ 29] : T
[ 30] : s A
[ 31] : # PUSH PI
[ 32] : $ PUSH log2_103
[ 33] : A ADD
[ 34] : $ PUSH log2_103
[ 35] : 8 DUP
[ 36] : C MUL
[ 37] : C MUL
[ 38] : T
[ 39] : s G
[ 40] : # PUSH PI
[ 41] : 8 DUP
[ 42] : 8 DUP
[ 43] : Q
[ 44] : C MUL
[ 45] : C MUL
[ 46] : $ PUSH log2_103
[ 47] : C MUL
[ 48] : T
[ 49] : s :
[ 50] : # PUSH PI
[ 51] : 8 DUP
[ 52] : 8 DUP
[ 53] : C MUL
[ 54] : C MUL
[ 55] : T
[ 56] : " PUSH 1
[ 57] : A ADD
[ 58] : s
[ 59] : ! PUSH 0
[ 60] : b CALL 467
[ 63] : b CALL 500
[ 66] : b CALL 457
[ 69] : 9
[ 80] : e JNE 86
[ 83] : 2 swap 0 2
[ 84] : S COS
[ 85] : 2 swap 0 2
[ 86] : : POP
[ 87] : 9
[ 98] : e JNE 104
[ 101] : 1 swap 0 1
[ 102] : S COS
[ 103] : 1 swap 0 1
[ 104] : : POP
[ 105] : b CALL 467
[ 108] : b CALL 500
[ 111] : b CALL 457
[ 114] : 9
[ 125] : e JNE 131
[ 128] : 2 swap 0 2
[ 129] : S COS
[ 130] : 2 swap 0 2
[ 131] : : POP
[ 132] : 9
[ 143] : e JNE 149
[ 146] : 1 swap 0 1
[ 147] : S COS
[ 148] : 1 swap 0 1
[ 149] : : POP
[ 150] : b CALL 467
[ 153] : b CALL 500
[ 156] : b CALL 457
[ 159] : 9
[ 170] : e JNE 176
[ 173] : 2 swap 0 2
[ 174] : S COS
[ 175] : 2 swap 0 2
[ 176] : : POP
[ 177] : 9
[ 188] : e JNE 194
[ 191] : 1 swap 0 1
[ 192] : S COS
[ 193] : 1 swap 0 1
[ 194] : : POP
[ 195] : b CALL 467
[ 198] : b CALL 500
[ 201] : b CALL 457
[ 204] : 9
[ 215] : e JNE 221
[ 218] : 2 swap 0 2
[ 219] : S COS
[ 220] : 2 swap 0 2
[ 221] : : POP
[ 222] : 9
[ 233] : e JNE 239
[ 236] : 1 swap 0 1
[ 237] : S COS
[ 238] : 1 swap 0 1
[ 239] : : POP
[ 240] : b CALL 467
[ 243] : b CALL 500
[ 246] : b CALL 457
[ 249] : 9
[ 260] : e JNE 266
[ 263] : 2 swap 0 2
[ 264] : S COS
[ 265] : 2 swap 0 2
[ 266] : : POP
[ 267] : 9
[ 278] : e JNE 284
[ 281] : 1 swap 0 1
[ 282] : S COS
[ 283] : 1 swap 0 1
[ 284] : : POP
[ 285] : b CALL 467
[ 288] : b CALL 500
[ 291] : b CALL 457
[ 294] : 9
[ 305] : e JNE 311
[ 308] : 2 swap 0 2
[ 309] : S COS
[ 310] : 2 swap 0 2
[ 311] : : POP
[ 312] : 9
[ 323] : e JNE 329
[ 326] : 1 swap 0 1
[ 327] : S COS
[ 328] : 1 swap 0 1
[ 329] : : POP
[ 330] : b CALL 467
[ 333] : b CALL 500
[ 336] : b CALL 457
[ 339] : 9
[ 350] : e JNE 356
[ 353] : 2 swap 0 2
[ 354] : S COS
[ 355] : 2 swap 0 2
[ 356] : : POP
[ 357] : 9
[ 368] : e JNE 374
[ 371] : 1 swap 0 1
[ 372] : S COS
[ 373] : 1 swap 0 1
[ 374] : : POP
[ 375] : b CALL 467
[ 378] : b CALL 500
[ 381] : b CALL 457
[ 384] : 9
[ 395] : e JNE 401
[ 398] : 2 swap 0 2
[ 399] : S COS
[ 400] : 2 swap 0 2
[ 401] : : POP
[ 402] : 9
[ 413] : e JNE 419
[ 416] : 1 swap 0 1
[ 417] : S COS
[ 418] : 1 swap 0 1
[ 419] : : POP
; last flag
[ 420] : r z
; chr(round((pi * pi + log2(e)) * log2(10) * log2(10))) == '}'
[ 421] : # PUSH PI
[ 422] : 8 DUP
[ 423] : C MUL
[ 424] : % PUSH log2_e1
[ 425] : A ADD
[ 426] : $ PUSH log2_103
[ 427] : 8 DUP
[ 428] : C MUL
[ 429] : C MUL
[ 430] : T
[ 431] : d JE 439
[ 434] : : POP
[ 435] : : POP
[ 436] : c JMP 564 ; Wrong
[ 439] : : POP
[ 440] : 9
[ 451] : d JE 596 ; Correct
[ 454] : c JMP 564
def calc(a, b):
return (ab, a+b)
[ 457] : 2 swap 0 2
[ 458] : 8 DUP
[ 459] : 2 swap 0 2
[ 460] : 8 DUP
[ 461] : 2 swap 0 2
[ 462] : C MUL
[ 463] : 2 swap 0 2
[ 464] : A ADD
[ 465] : 2 swap 0 2
[ 466] : a RET
[ 467] : r e
[ 468] : b CALL 537
[ 471] : r r
[ 472] : b CALL 537
[ 475] : " PUSH 1
[ 476] : " PUSH 1
[ 477] : A ADD
[ 478] : # PUSH PI
[ 479] : C MUL
[ 480] : C MUL
[ 481] : $ PUSH log2_103
[ 482] : 8 DUP
[ 483] : A ADD
[ 484] : T
[ 485] : $ PUSH log2_103
[ 486] : 8 DUP
[ 487] : C MUL
[ 488] : C MUL
[ 489] : T
[ 490] : $ PUSH log2_103
[ 491] : C MUL
[ 492] : T
[ 493] : D DIV
[ 494] : 8 DUP
[ 495] : R SIN
[ 496] : B SUB
[ 497] : C MUL
[ 498] : 1 swap 0 1
[ 499] : a RET
[ 500] : r 0
[ 501] : b CALL 537
[ 504] : r p
[ 505] : b CALL 537
[ 508] : " PUSH 1
[ 509] : " PUSH 1
[ 510] : A ADD
[ 511] : # PUSH PI
[ 512] : C MUL
[ 513] : C MUL
[ 514] : $ PUSH log2_103
[ 515] : 8 DUP
[ 516] : A ADD
[ 517] : T
[ 518] : $ PUSH log2_103
[ 519] : 8 DUP
[ 520] : C MUL
[ 521] : C MUL
[ 522] : T
[ 523] : $ PUSH log2_103
[ 524] : C MUL
[ 525] : T
[ 526] : D DIV
[ 527] : 8 DUP
[ 528] : S COS
[ 529] : " PUSH 1
[ 530] : A ADD
[ 531] : 1 swap 0 1
[ 532] : R SIN
[ 533] : C MUL
[ 534] : C MUL
[ 535] : 1 swap 0 1
[ 536] : a RET
func is_ascii(char c)
[ 537] : 1 swap 0 1
[ 538] : # PUSH PI
[ 539] : 8 DUP
[ 540] : C MUL
[ 541] : # PUSH PI
[ 542] : C MUL
[ 543] : T
[ 544] : " PUSH 1 ; 31
[ 545] : A ADD ; 32
[ 546] : g JG 564
[ 549] : $ PUSH log2_103
[ 550] : 8 DUP
[ 551] : C MUL
[ 552] : $ PUSH log2_103
[ 553] : C MUL
[ 554] : % PUSH log2_e1
[ 555] : A ADD
[ 556] : $ PUSH log2_103
[ 557] : C MUL
[ 558] : T
[ 559] : h JLE 564 ; 127
[ 562] : 1 swap 0 1
[ 563] : a RET
[ 564] : # PUSH PI
[ 565] : % PUSH log2_e1
[ 566] : C MUL
[ 567] : $ PUSH log2_103
[ 568] : A ADD
[ 569] : # PUSH PI
[ 570] : 8 DUP
[ 571] : C MUL
[ 572] : C MUL
[ 573] : T
[ 574] : s N
[ 575] : # PUSH PI
[ 576] : $ PUSH log2_103
[ 577] : A ADD
[ 578] : $ PUSH log2_103
[ 579] : 8 DUP
[ 580] : C MUL
[ 581] : C MUL
[ 582] : T
[ 583] : s G
[ 584] : " PUSH 1
[ 585] : # PUSH PI
[ 586] : A ADD
[ 587] : $ PUSH log2_103
[ 588] : 8 DUP
[ 589] : C MUL
[ 590] : C MUL
[ 591] : T
[ 592] : s .
[ 593] : c JMP 629
[ 596] : # PUSH PI
[ 597] : " PUSH 1
[ 598] : E NEG
[ 599] : A ADD
[ 600] : $ PUSH log2_103
[ 601] : 8 DUP
[ 602] : 8 DUP
[ 603] : C MUL
[ 604] : C MUL
[ 605] : C MUL
[ 606] : T
[ 607] : s O
[ 608] : $ PUSH log2_103
[ 609] : 8 DUP
[ 610] : & PUSH log10_20
[ 611] : # PUSH PI
[ 612] : A ADD
[ 613] : $ PUSH log2_103
[ 614] : A ADD
[ 615] : C MUL
[ 616] : C MUL
[ 617] : T
[ 618] : s K
[ 619] : # PUSH PI
[ 620] : 8 DUP
[ 621] : C MUL
[ 622] : $ PUSH log2_103
[ 623] : C MUL
[ 624] : T
[ 625] : s !
[ 626] : c JMP 629
[ 629] : # PUSH PI
[ 630] : 8 DUP
[ 631] : C MUL
[ 632] : T
[ 633] : s
[ 634] : q3. 동작 분석
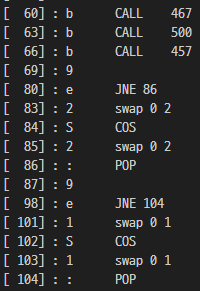
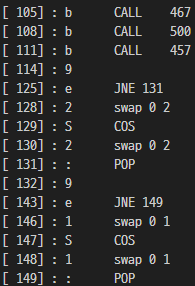
...
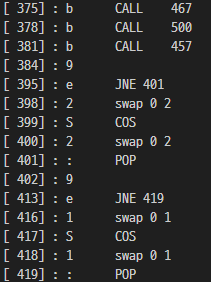
위처럼 467 500 457 CALL 후 비교 2번 하는 구조가 총 8번 반복된다.
- 467 function
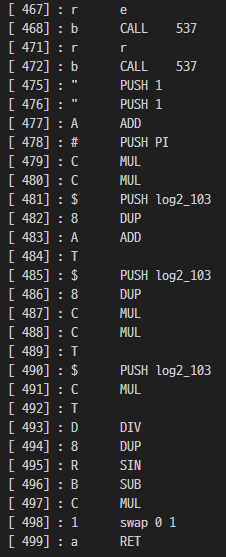
입력(r) 을 2번 받고 537을 CALL 하는 것을 볼 수 있다.
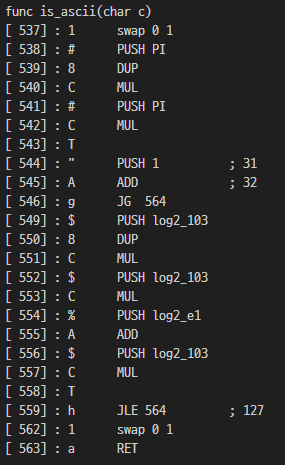
537 은 32 <= 127 <= 인지 검증한다. 대충 is_ascii 로 이름지어줬다.
다시 467로 돌아오면 특정 연산을 한다.
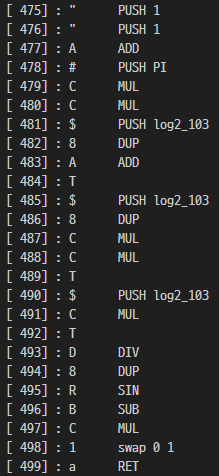
l2t = log2(10)
print(round(round(round(2 * l2t) * l2t * l2t) * l2t))
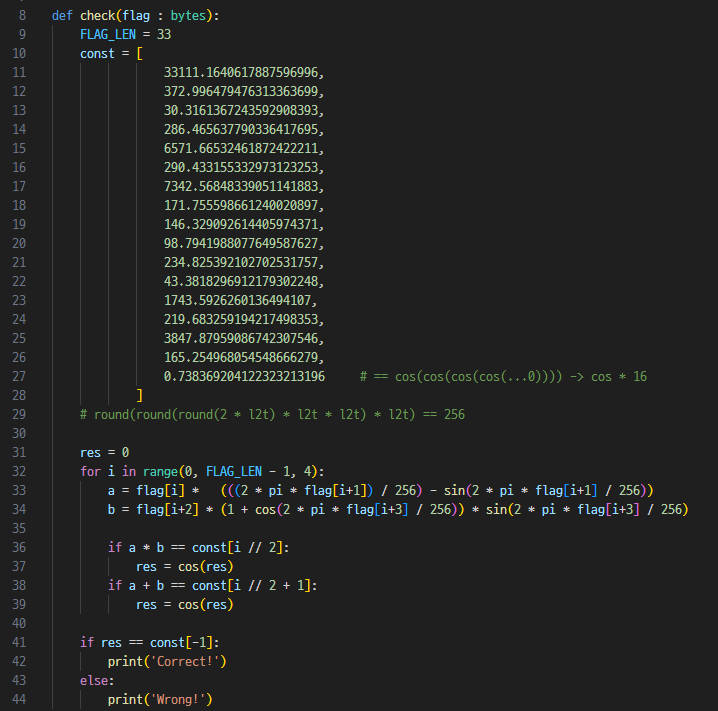
# 256두 번째 log2_10 을 사용하는 상수값은 위 코드처럼 256 이고 앞은 2 * pi * input[0] 임을 알 수 있다.
flag[i] * (((2 * pi * flag[i+1]) / 256) - sin(2 * pi * flag[i+1] / 256))처럼 정리할 수 있다.
- 500 function
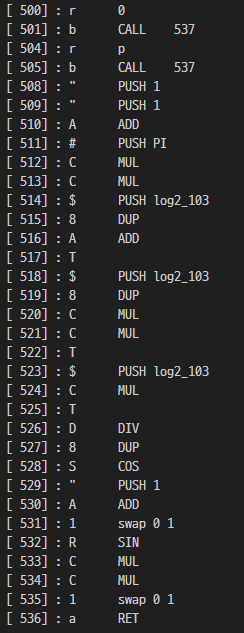
마찬가지로 입력 2번 537 2번 호출한다.
이후 연산도 아래처럼 정리한다.
flag[i+2] * (1 + cos(2 * pi * flag[i+3] / 256)) * sin(2 * pi * flag[i+3] / 256)- 457 function
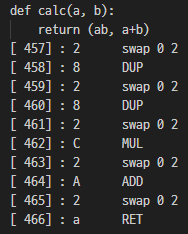
return 으로 표현했지만 st 0 / 1 에 b / a 를 설정하면 ab / a + b 로 st 0 / 1을 바꿔준다.
- 비교
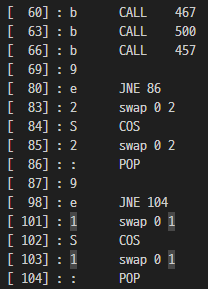
467 500 457을 CALL 한 후 2번의 비교를 한다.
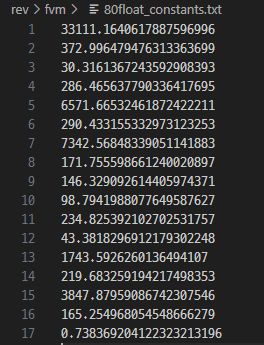
"9" instruction 은 10 byte constant float 를 push 한다.
따라서 a*b 와 a + b 가 각각 특정 상수와 같으면 cos 연산을 한다.
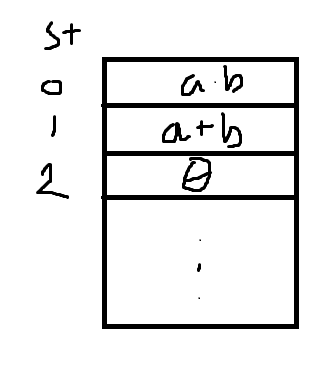
st2는 처음에 0으로 세팅되어있고, 위의 비교가 참이면 cos 연산을 한다.
즉 정답을 입력했을 때 총 16번 cos 연산을 할 것이고, 이 값은 0.7383692041223232 가 된다.
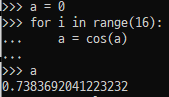
맨 마지막에 이 값이 0.7383692041223232 인지 체크한다.
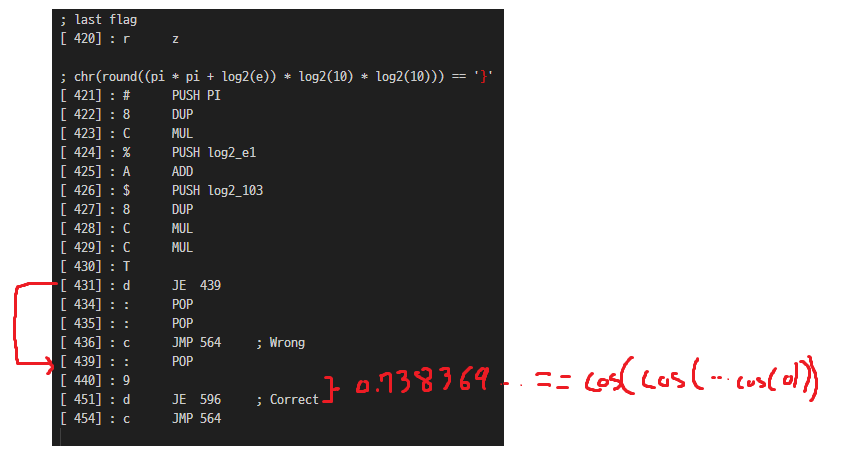
그리고 맨 마지막 글자가 } 인지 체크한다.
아까 467 500 457 구조가 총 8 번 있었고, 각 검사마다 4글자씩 검사하기 때문에 8 * 4 , 32글자에 마지막 } 까지 flag가 33글자임을 알 수 있따.
비교하는 10byte float 상수값들을 구하기 위해 다음 코드를 사용한다.
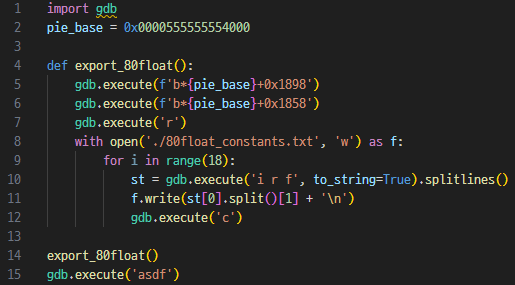
$ gdb -x log.py ./fvm > /dev/null
4. 정연산
5. 역연산
a, b, c, d 를 flag 의 4 글자씩이라 할 때, (b, d / 256 생략)
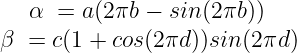
이고, alpha * beta 와 alpha + beta를 알기 때문에 alpha와 beta 각각의 값을 알 수 있다.
이후 256 * 256 브포는 돌릴만하므로 a,b / c, d 따로 오차가 적은 경우를 선택한다.
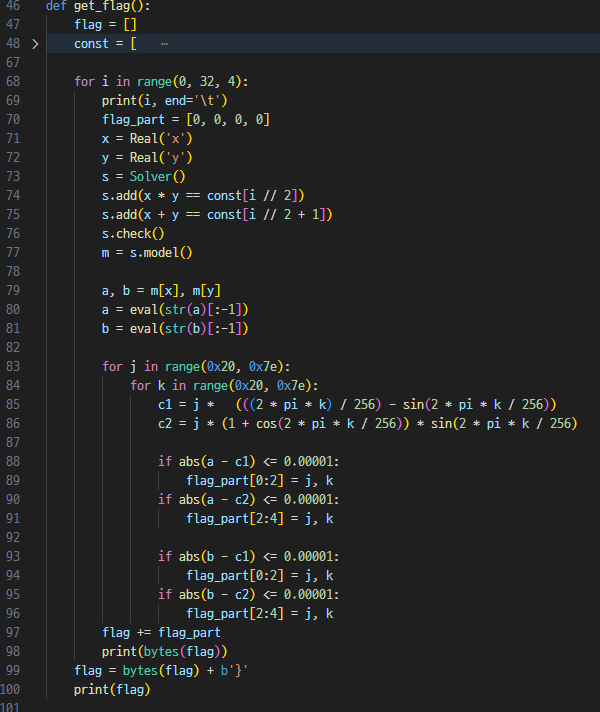
이때 어떤 값이 alpha고 beta인지 모르므로 4경우를 다 체크한다.
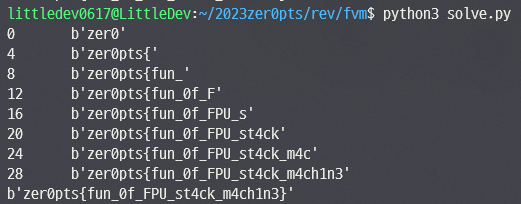
FLAG : zer0pts{fun_0f_FPU_st4ck_m4ch1n3}
'CTF Writeup' 카테고리의 다른 글
| zer0ptsCTF 2023 - decompile_me Writeup (0) | 2023.07.19 |
|---|---|
| zer0ptsCTF 2023 - mimikyu Writeup (0) | 2023.07.19 |
| 2023 Codegate UNIV division writeup (0) | 2023.06.18 |
| Defcon 2023 Qualifier - kkkkklik writeup (0) | 2023.05.31 |
| 2022 Incognito CTF Writeup (0) | 2023.03.26 |